
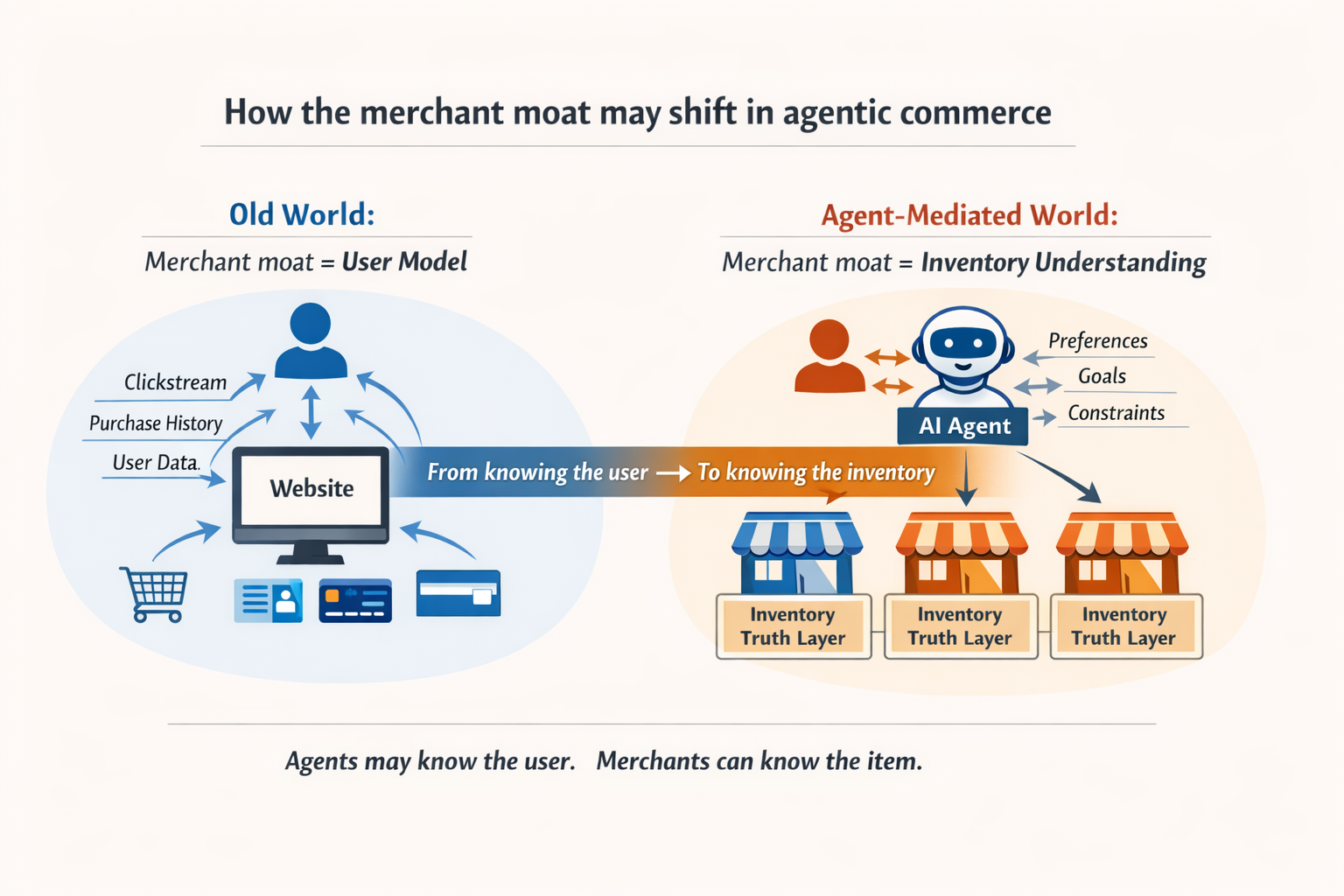
In my previous post, I argued that site personalization may be entering a discontinuity.
Historically, the site knew the user best — at least within the boundaries of its own property. It could observe browsing, clicks, purchases, watch history, dwell time, returns, and other forms of first-party behavioral signal, and use those to personalize ranking, promotions, and experience design.
But in an agent-mediated world, that advantage may weaken.
If the user’s primary interface increasingly becomes an agent, then the most complete and portable model of the user may no longer live on the merchant’s site. It may live with the agent: a system that can accumulate preferences, constraints, goals, and context across many sites and sessions.
That raises a natural question:
If agents increasingly know the user, what remains as the merchant’s moat?
My answer: For many merchants and marketplaces, especially those sitting on large amounts of unstructured supply-side data, the moat may increasingly shift from knowing the user to knowing the inventory.
And that is not a small distinction.
The hidden asset many merchants already have
Many merchants and marketplaces are already sitting on a massive proprietary asset: a merchant-owned corpus of unstructured listing data.
This includes titles, descriptions, specs buried in free text, seller Q&A, images, and sometimes even video. In categories like collectibles, electronics, auto parts, fashion, and used goods, that corpus often contains much of the actual truth about the inventory — far more than the neat structured catalog fields do.
Seen this way, the corpus is not just messy content. It is a latent combination of:
- a product graph,
- a compatibility graph,
- a condition and authenticity layer,
- and a shopper-intent map waiting to be mined.
If properly modeled, it can power all three futures I discussed in the earlier post:
- agent-only, where the agent ranks,
- merchant-only, where the site still personalizes directly,
- hybrid, where agent and merchant exchange signals.
The common pattern is this: the merchant uses unstructured supply data to make its inventory more legible, more comparable, and more trustworthy to an agent — without requiring the agent to reveal the full private user model.
From listings to an agent-readable catalog
The first and most obvious move is to convert unstructured listings into a structured, agent-readable catalog.
That means extracting normalized attributes from text and images:
- brand,
- model,
- size,
- compatibility,
- condition,
- materials,
- dimensions,
- era or year,
- bundle contents,
- authenticity cues,
- defects,
- inclusions and exclusions.
It also means resolving seller language into controlled vocabulary. Every marketplace has its own dialect of seller-isms: “NWOT,” “like new,” “open box,” “untested,” “OEM,” “no returns,” and countless category-specific variants. If those terms are not normalized, agents — and often even internal ranking systems — are left to reason over ambiguity.
Finally, it means canonicalizing variants: mapping what may be 50 slightly different descriptions of the same product or variant into a coherent product spine.
Why does this matter?
Because in an agent-only world, the agent can rank much better if the feed contains clean, trustworthy structured fields such as:
- “fits iPhone 15 Pro,”
- “inseam 32,”
- “ships by Friday,”
- “OEM genuine,”
- “battery health 91%,”
- “graded PSA 9.”
And in a hybrid world, it lets the merchant precisely match against a preference payload sent by the agent, whether structured or natural language:
needs wide toe box, size 10.5, neutral colors
prefer graded 9 or higher
avoid screen replacement
arrives by Friday
What makes unstructured content uniquely valuable is that sellers often reveal critical information only in prose and photos:
- “tiny scratch near logo”
- “includes charger but not box”
- “rare 2017 print”
- “works great except Face ID”
- “manual missing”
- “resealed”
These are precisely the details that structured catalog fields often miss — and precisely the details that can make the difference between delight and disappointment in an agent-mediated purchase.
Multimodal embeddings: the bridge between natural-language intent and real inventory
The second major move is to build multimodal embeddings over the catalog.
At a minimum, that means:
- text embeddings for titles and descriptions,
- image embeddings for listing photos,
- and ideally fused multimodal representations of the listing as a whole.
This supports several capabilities at once:
- semantic search,
- “more like this” retrieval across a messy catalog,
- deduplication and near-duplicate detection,
- attribute suggestion and autofill for sellers,
- and deeper item understanding for ranking.
This layer becomes especially important because agents will often express intent in natural language, not in the rigid taxonomies that existing catalogs expect.
A user may ask for:
- “a mid-century brass desk lamp with a pull chain”
- “a vintage comic with minimal spine wear”
- “a used MacBook with USB-C charging, 16GB RAM, and no screen replacement”
Embeddings are the bridge between “agent speaks natural language” and “catalog speaks structured constraints.”
In the agent-only model, this lets merchants return high-recall candidate sets even when the agent query is broad or conversational.
In merchant-only and hybrid models, these representations also become powerful ranking features, especially for cold-start items and sparse-user scenarios.
Trust becomes a ranking primitive
Agent-mediated discovery will likely be much less forgiving than human browsing when it comes to trust.
A human shopper may click around, inspect photos, compare listings, and tolerate some ambiguity. An agent acting on a user’s behalf has a stronger mandate: avoid returns, avoid fraud, avoid counterfeits, avoid disappointment.
That makes trust a first-class ranking primitive.
Unstructured data can be used to build a listing quality and truthfulness layer, including signals such as:
- completeness,
- clarity,
- ambiguity,
- consistency between text and images,
- missing critical fields,
- exaggerated or manipulative claims,
- condition evidence,
- authenticity evidence,
- delivery reliability,
- return-risk proxies.
This can become extremely valuable in the agent-only model. Even if the agent owns the final ranking, the merchant can expose trust signals as feed fields:
- quality score,
- authenticity confidence band,
- condition confidence,
- compatibility confidence,
- return-risk estimate,
- delivery reliability.
That is a very different proposition from merely exposing title, price, and category.
In a hybrid model, those same signals can be tuned to user tolerance. One user may accept cosmetic wear but not functional defects. Another may happily buy refurbished electronics but only if battery health exceeds a threshold. Another may buy ungraded collectibles but only with strong provenance evidence.
In other words, trust does not just protect the platform. It becomes part of the personalization surface.
Listings need to become answerable
There is another subtle but important shift.
Agents want to talk.
Traditional listings are written for human scanning, not for conversational interaction. They are often verbose where they should be precise, vague where they should be explicit, and silent where the most important questions lie.
That suggests merchants should convert raw listing content into conversational merchandising assets.
For each listing, one can generate an agent-facing summary or “card” containing:
- what the item is,
- key specs,
- what is included,
- condition highlights,
- shipping and returns,
- top uncertainties,
- and the 1–3 most important clarifying questions.
This reduces hallucination risk and makes inventory more browsable through conversation.
For example, instead of dumping a raw seller paragraph, an agent card might say:
- What it is: iPhone 14 Pro, 256GB, unlocked, deep purple
- Condition: light scratches on lower frame, screen clean
- Included: charging cable only
- Risk flags: battery health not shown, activation-lock status not explicitly pictured
- Clarifying question: Can the seller show the reset/setup screen?
Clarifying questions are the 1–3 highest-value next questions an agent should ask when important uncertainty remains.
These assets are useful not only for external agents, but also for the merchant’s own conversational assistants and guided-discovery experiences.
The catalog knowledge graph underneath
Especially in marketplaces with long-tail and used goods, “the product” is not merely a SKU.
It is a web of relations:
- product ↔ model ↔ generation
- item ↔ compatibility ↔ accessories
- listing ↔ substitute ↔ complement
- collectible ↔ edition ↔ rarity ↔ provenance
Unstructured data can be used to extract entities and relations and build a catalog knowledge graph that links listings to canonical nodes and to one another.
This improves retrieval and recommendation in ways that are very hard to reproduce with keyword matching alone.
A user or agent can ask:
give me compatible chargers for a ThinkPad T14 Gen 2 under $25 arriving by Friday
or
show me graded copies of this card, then ungraded near-mint alternatives under $200
That kind of interaction requires more than search. It requires relational understanding.
Examples from Collectibles and electronics
Let’s consider two categories to illustrate these ideas: collectibles and electronics.
They are almost ideal “unstructured-data-first” categories because the truth often lives in photos and prose, and because value hinges on subtle, high-stakes attributes.
Collectibles
For collectibles, the relevant schema may include:
- category subtype,
- franchise or series,
- creator, publisher, or manufacturer,
- year or era,
- edition or variant,
- rarity markers,
- condition grade claimed,
- condition inferred,
- defects,
- completeness,
- packaging state,
- authenticity claims,
- provenance type,
- grading service, grade, and certification number.
What matters here is not just extraction, but confidence and evidence.
A strong collectibles feed should expose signals such as:
- authenticity confidence
- condition confidence
- completeness risk
- edition ambiguity risk
An agent-facing collectible card might summarize:
- what the item is,
- why it matters,
- what condition issues are visible,
- how strong the authenticity evidence is,
- and what still needs clarification.
This is immensely useful across all three models.
In an agent-only world, the merchant becomes the most legible and trustworthy supply endpoint. In a merchant-only world, these derived fields become ranking features for different collector segments. In a hybrid world, the merchant can match agent-supplied constraints such as:
- authenticated signature only
- graded 9 or above
- avoid yellowing
- under $400
Electronics
Electronics present a different but equally rich problem.
Here, the schema may include:
- brand,
- model,
- model number,
- storage, RAM, CPU/GPU, screen size, ports,
- region or variant,
- compatibility fields,
- condition inferred,
- battery health,
- repair history,
- water-damage flags,
- included accessories,
- warranty status,
- return-policy quality.
The key challenge is that the cost of ambiguity is high. A small misunderstanding about model number, carrier lock, charger type, or prior repair can turn into an expensive return.
That makes several trust signals especially valuable:
- functional confidence — does the listing show the device powered on, with key screens visible?
- compatibility confidence — do model and region details support the stated compatibility?
- fraud-friction score — partial serial/IMEI evidence, timestamped photos, consistency between on-device screens and claimed specs
- return-risk score — untested language, activation-lock ambiguity, vague claims such as “works great”
An agent-facing electronics card might summarize:
- exact model and specs,
- compatibility,
- functional checks demonstrated,
- battery or storage health,
- risk flags,
- and the top clarifying question.
This makes the merchant’s inventory safer to browse and safer to buy through an agent.
The inventory truth layer as the new moat
The most important idea here is that all of these capabilities can roll up into a single strategic asset: an inventory truth layer.
That truth layer is more than enriched metadata.
It is a representation of what the merchant knows about the item:
- what it is,
- how confident the system is,
- what evidence supports that,
- what risks remain,
- how it compares to nearby alternatives,
- and how well it matches a given need.
This truth layer can become:
- the quality backbone of agent-facing feeds,
- the feature backbone of merchant ranking systems,
- and the safety backbone of hybrid preference exchange.
That is why I think the framing question matters.
If agents increasingly know the user, then merchants and marketplaces need a different defensible advantage.
For many of them, that advantage may be this:
Agents may know the user.
But marketplaces can know the item — its identity, condition, compatibility, authenticity, and purchase risk — better than anyone else.
A practical build sequence
If I were building toward this capability, the minimum viable sequence would probably look like this:
- Attribute extraction, category by category, from text and images
- Multimodal embeddings for retrieval and similarity
- Quality and trust layers exposed as ranking features and feed fields
- Canonical product spines / knowledge graphs for compatibility-heavy categories
- Agent-facing representations such as cards, summaries, and clarifying questions
And throughout, I would insist on a two-tier truth model:
- raw claim layer — what the seller said, kept immutable and auditable
- inferred layer — what the system derived, with confidence and evidence pointers
That distinction matters because inventory understanding is only as trustworthy as its provenance. Seller claims, model inferences, and verified evidence should not be collapsed into a single undifferentiated truth layer.
So where does this leave personalization?
It leaves it in a more interesting place.
Personalization does not disappear. User understanding still matters. Loyalty, pricing, relationship management, service recovery, and direct experiences will continue to depend on it.
But if the interface shifts toward agents, then the merchant’s informational advantage may increasingly lie elsewhere.
Not only in knowing who the user is.
But in knowing what the inventory really is.
And perhaps that is the next moat:
not just a better user model,
but a better representation of supply.
If the first era of personalization was about knowing the user, the next one may increasingly be about making inventory legible, comparable, trustworthy, and computable for agents.
That feels like a strategic shift.
—SriG

Leave a comment