
A/B testing is one of the most valuable tools in modern digital product development. Used well, it gives teams something rare and precious: causal evidence. Instead of relying on hierarchy, opinion, intuition, or the most persuasive person in the room, teams can expose different users to different experiences and measure what actually happens.
The advance has been substantial. The controlled-experiment literature, especially the work of Ron Kohavi and collaborators, has made a strong case for online experiments as a practical way to understand whether product changes affect user-observable behavior. One of the great benefits of A/B testing is that it forces organizations to listen to customers rather than only to internal opinion [1].
The best experimentation cultures are cross-functional. Product leaders help frame customer problems, business priorities, hypotheses, and tradeoffs. Designers help shape experiences that users can understand and trust. Applied scientists and engineers develop the models, systems, and technical capabilities that make new experiences possible. Analysts help ensure that metrics, instrumentation, and interpretation are sound.
A culture with experimentation is far better than one driven mainly by opinion, executive preference, or untested assumptions.
I saw this firsthand at eBay, where I worked closely with product, design, analytics, and engineering partners as an applied research and engineering leader. Our team built and supported a high-velocity experimentation culture, running on the order of a thousand tests a year — a reflection of technical maturity, organizational discipline, and a serious commitment to learning from customers.
But success at A/B testing can also create a subtle problem. Because experimentation is rigorous, scalable, and dashboard-friendly, organizations can start asking it to do too much.
A/B testing can tell us whether a change worked. It can help us learn from surprising results. It can accumulate many incremental wins into significant business impact. It can also evaluate bold changes when those changes are mature enough to put in front of customers. But it cannot, by itself, tell us what was worth building, whether users truly understood the experience, or whether we are slowly degrading the customer relationship in pursuit of short-term gains.
This distinction matters especially in ecommerce discovery and personalized recommendations, where the user experience is not simply a set of screens. It is an evolving relationship among buyer intent, product understanding, ranking, recommendations, ads, seller inventory, trust, and long-term customer value.
A/B testing is most powerful when it sits inside a full product-learning loop: discovery, design, development, experimentation, analysis, and learning.
What A/B testing is good at
A/B testing excels at comparing well-formed alternatives.
Most A/B tests compare the current production experience, the control, with a hypothesized improvement, the treatment. This is powerful because it forces a proposed change to prove itself against the real experience users have today, not against an abstract ideal.
If we have two mature versions of a product experience, a meaningful success metric, clean instrumentation, sufficient traffic, and a reasonable expectation that the effect can be detected, an A/B test is often the right tool. In ecommerce, this can apply to checkout flows, product pages, listing pages, promotions, ranking changes, recommendation modules, merchandising treatments, messaging, and page layout.
Incremental wins from A/B testing accumulate meaningfully. In a large-scale ecommerce system, incremental improvements are not trivial. A small lift in search success, conversion, recommendation relevance, checkout completion, or buyer confidence can represent enormous customer and business value.
Some of these improvements may look modest in isolation: increasing the resolution of product images in a recommendation carousel, allowing more lines of text so buyers can see more of the product title, or adjusting the balance between predicted conversion probability and ad rate when ranking candidate recommendations. None of these changes, by itself, may sound like a fundamental redesign of the experience, but each can remove friction, improve buyer confidence, or make the ranking system slightly better aligned with user and business value.
Many of the most durable gains in mature platforms come this way: not from a single breakthrough, but from compounding improvements over time.
Research on ecommerce experimentation reinforces this point, but also highlights how much it matters to test with specific hypotheses rather than generic ones. A meta-analysis of 2,732 A/B tests across 252 ecommerce companies found that experimental impact varies substantially depending on funnel location and intervention type [2] — meaning the same kind of change can behave very differently on a product listing page, a product detail page, or in checkout. Teams that test with clear hypotheses about the buyer journey tend to learn more than those that distribute experiments indiscriminately across surfaces in the expectation that some metric will respond.
A/B testing is also not limited to incremental improvements. It can and should be used to evaluate larger product bets when those bets are mature enough to put in front of users. A redesigned discovery experience, a new recommendation strategy, a new ranking architecture, or a new way for buyers to express intent can all be evaluated experimentally.
All told, A/B testing answers a specific question:
Which of these alternatives performs better under these conditions, for these users, on these metrics, during this time window?
That is a valuable question, but it is not the same as asking:
What experience should we have built in the first place?
Whether the change is incremental or bold, answering that broader question requires the experiment to be embedded in a thoughtful learning process — one that begins before the test is designed and continues long after the results are read.
The risk of compressing the product-learning loop
The risk does not originate in A/B testing itself, but in what happens when experimentation velocity becomes the dominant organizational goal.
A healthy product organization operates as a continuous loop: product discovery, design, development, experimentation, analysis, and learning. Discovery helps us understand the customer problem. Design explores possible solutions. Development makes them real. Experimentation measures impact. Analysis interprets the result. Learning feeds the next cycle.
When the drive for velocity becomes too strong, the loop is compressed. Discovery becomes thinner. Design exploration narrows. Development favors smaller, lower-risk changes. Experiment analysis becomes more transactional. Learning is reduced to whether the dashboard says ship, iterate, or stop.
That is when experimentation begins to favor incremental optimization — not because A/B testing requires incrementalism, but because the organizational system around it rewards short-cycle, easy-to-isolate, easy-to-measure changes. Incremental improvements matter; at ecommerce scale, small gains in search success, conversion, or recommendation relevance can accumulate into genuine business value. The risk lies in allowing this orientation to become the default rather than one mode among several.
A roadmap dominated by short-cycle experiments can crowd out deeper work: new experience concepts, better buyer intent modeling, richer catalog understanding, more trustworthy personalization, or a more thoughtful balance between organic results, recommendations, and ads.
Two related problems follow from this dynamic.
First, a team may be optimizing an experience that is considerably short of the best possible one. A/B testing can improve the current experience while leaving the product well below what it might otherwise become. A team can improve a recommendation carousel, for example, while missing the possibility that buyers need a different way to express intent, compare products, understand recommendations, or control personalization.
Second, and relatedly, there is the matter of opportunity cost. Time and resources devoted to optimizing a suboptimal experience are unavailable for the development of a superior one. Experimentation capacity, engineering attention, design energy, analytical focus, and organizational patience are all finite, and a roadmap full of locally rational tests can crowd out the deeper work needed for a step-change improvement. This cost is real even when each individual test is well-designed and cleanly executed.
A/B testing can help an organization climb the hill it currently occupies; without sufficient discovery, design exploration, and post-experiment learning, however, it may remain unaware that a better hill exists nearby.
This is particularly important in ecommerce discovery. A team can test many versions of a recommendation module and still miss the deeper issue: buyers may not trust the recommendations. They may not understand why items are being shown. The recommendations may be too repetitive. The catalog representation may be poor. The product attributes may not capture what actually matters to buyers. The experience may be too ad-heavy. The buyer may not have enough control over the direction of personalization.
In such cases, A/B testing refines an existing concept without generating a new one.
Getting to a meaningfully better experience often requires deeper work: user research, behavioral analysis, search-log analysis, journey mapping, marketplace diagnosis, catalog understanding, recommender-system development, and product imagination. The best solution may not be a better carousel. It may be a different way of expressing intent, a richer product ontology, a new explanation model, a better balance between relevance and diversity, or a different relationship between organic results, ads, and recommendations.
A/B testing is a decision tool, not a substitute for the full work of product discovery, design, and technical solution development.
A/B test analysis can still lead to deeper learning
There is an important counterpoint: A/B testing does not have to trap teams in local optimization, provided it is integrated into a proper learning loop.
A surprisingly positive result can reveal that the team misunderstood user behavior. A surprisingly negative result can expose a hidden dependency, a usability issue, a trust problem, a marketplace effect, or a flawed assumption about buyer intent. In this sense, the value of an A/B test extends beyond the ship/no-ship decision to the analysis that follows.
A well-run post-experiment review can ask:
- Why did this work?
- Why did this fail?
- Which segments moved?
- Which users were harmed?
- Did the result vary by category, query type, device, seller type, or buyer intent?
- Did the metric move for the reason we expected?
- Did guardrails reveal a hidden cost?
- Did the result suggest a deeper opportunity?
This kind of analysis can help teams escape local optimization. A failed experiment may point to a more important product problem. A successful experiment may reveal a principle that can be applied more broadly. A confusing experiment may lead to better instrumentation, new user research, or a rethinking of the original hypothesis.
Of course, not every experiment will yield strategic insight; sometimes the finding is simply that users preferred one label or layout over another, and that is a legitimate outcome. The important point is that when results are surprising, ambiguous, unusually strong, unusually weak, or strategically important, they should be treated as opportunities for deeper learning. The danger lies not in local testing itself, but in treating experiment readouts as endpoints rather than as evidence that can inform a broader understanding of buyers, systems, and product direction.
User testing should precede large-scale experimentation
Another risk is using A/B testing to evaluate user interfaces that have not yet passed basic usability and comprehension checks.
This happens often in large organizations, usually for understandable reasons. A team has a new experience, wants to make a data-driven decision, and launches an experiment. If the variant loses, the team knows it lost — but often does not know why.
Did users miss the filter? Did they misunderstand the sort order? Did they think the recommendation module was an ad? Did they fail to notice an important product attribute? Did the layout obscure shipping cost, condition, returnability, seller location, or delivery date? Did the experience create hesitation because users could not understand why certain items were being shown?
An A/B test can reveal that behavior changed; it generally cannot explain the source of a user’s confusion.
For these questions, user testing a design is often faster, cheaper, and more informative. Observing even a small number of users interact with a prototype or new experience can reveal problems that a large-scale experiment may only detect indirectly. The Nielsen Norman Group has long argued for the practical value of small, iterative usability studies, famously noting that testing with around five users can uncover many usability problems with a strong benefit-cost ratio [3][4].
The exact number is less important than the principle: when the problem is one of usability, comprehension, or trust, direct observation is often the appropriate first step.
A useful rule of thumb is:
User testing tells us whether users can understand and use the experience. A/B testing tells us whether a usable experience changes behavior at scale.
This sequencing matters. Before A/B testing a new personalized recommendation experience, we should already have some confidence that buyers understand what they are seeing. Do they know why these items are recommended? Can they distinguish sponsored content from organic recommendations? Do they know how to recover when recommendations are wrong? Do they trust the labels and explanations? Can they complete the task?
Where the answer to these questions is uncertain, the experiment is premature.
This does not mean teams should avoid experimentation. It means that user testing and experimentation should complement each other. User testing can improve the quality of what we test; A/B testing can then measure the impact of mature alternatives at scale.
The short-term metric trap
A deeper risk is that experimentation programs tend to favor metrics that can reach statistical significance quickly.
In many ecommerce settings, that means metrics such as clicks, page views, product detail views, add-to-cart, short-term conversion, revenue per visitor, ad clicks, or recommendation module CTR.
These metrics are not without value — many are central to how ecommerce platforms understand buyer behavior — but they are incomplete on their own.
Many of the most important effects in ecommerce discovery and personalization are slow, cumulative, sparse, or hard to attribute. Buyer trust does not collapse in one session. Ad fatigue may build gradually. Occasional irrelevant recommendations may not register as a measurable loss in a two-week experiment, but they may teach buyers to ignore recommendation modules over time. A highly exploitative personalization strategy may increase immediate clicks while narrowing the buyer’s sense of discovery. A more aggressive ad treatment may raise short-term monetization while slowly making the experience feel less trustworthy.
The consequences are not limited to product metrics; they can affect the brand. When buyers repeatedly encounter excessive ads, irrelevant recommendations, low-quality results, or confusing discovery experiences, they may not consciously diagnose the problem. They may simply begin to trust the platform less, browse less often, or begin certain shopping journeys elsewhere. These effects may unfold over long periods and may be very difficult to measure, but they remain a genuine part of the customer experience.
Short experiment windows are often necessary and useful. The risk arises when the metrics that can reach significance within them become the sole definition of customer value. An organization that depends primarily on two-week A/B tests will tend, over time, to optimize for effects that materialize in two weeks.
This is one reason mature recommender-system organizations attend to longer-term satisfaction, not just immediate interaction. Netflix’s published work on recommender systems describes an evaluation approach that combines offline experimentation using historical engagement data with A/B testing focused on member retention and medium-term engagement [5] — a reminder that recommender-system evaluation should look beyond immediate interaction metrics, and a lesson that applies directly to ecommerce.
A recommendation system that increases clicks but reduces trust is not a success. An ads layout that increases short-term revenue but makes the marketplace feel less useful is extracting value from the customer relationship. A ranking change that improves near-term conversion while reducing long-tail discovery may create hidden marketplace costs.
Click-through rate is often a useful diagnostic signal; it should not function as the primary criterion for product decisions.
For buyer-facing ecommerce experiences, we should care about whether buyers find what they want, discover things they value, trust the platform, return over time, and continue to see the marketplace as worth visiting. These outcomes are more difficult to quantify, but that difficulty does not diminish their reality or their importance to the long-term health of the platform.
Why personalization makes this harder
Personalization complicates A/B testing in ways that are easy to underestimate. In a traditional UI experiment, we can say that users in treatment saw version B and users in control saw version A. In personalized recommendations, two users assigned to the same treatment may see entirely different products, layouts, explanations, or ranking decisions. Some users may never become eligible for the personalized treatment at all. Others may receive a strong dose of the new experience because of their history, category, session behavior, device, location, or inferred intent. This heterogeneity makes the average treatment effect considerably harder to interpret.
Suppose a new recommendation model improves average conversion by showing more popular, high-converting items. The aggregate result may look positive, yet the same change may reduce discovery for niche buyers, narrow the experience for collectors, hurt cold-start sellers, or train buyers to ignore recommendation modules that feel repetitive.
Aggregate metrics can also conceal pockets of poor experience. A treatment may improve average conversion while creating visibly worse experiences for specific buyer groups, product categories, price bands, query types, or shopping missions. A ranking or recommendation change may work well for mainstream categories but perform poorly for collectibles, parts and accessories, refurbished goods, or long-tail inventory. These pockets may be too small to move the overall metric, but they are very real to the buyers who encounter them.
A high-intent buyer who knows what they want may benefit from focused recommendations. A browsing buyer may need diversity, novelty, and inspiration. A returning buyer with a rich history may benefit from personalization, while a new buyer may need clearer navigation and better ways to express intent.
In personalized systems, the average treatment effect is frequently not the most informative quantity.
This does not render A/B testing invalid; it means the experiment requires more careful interpretation. We need to understand eligibility, exposure, treatment-on-treated effects, segment-level impact, cold-start behavior, category differences, diversity, coverage, novelty, repetition, and long-term outcomes.
Personalization is not simply a feature change; it is a policy that determines, moment by moment, what different buyers are shown. Evaluating such a policy requires more than a single aggregate readout.
Ecommerce discovery is also a marketplace intervention
Ecommerce discovery is not only a buyer experience problem. It is also a marketplace allocation problem.
Search, recommendations, ads, ranking, and merchandising determine how attention is distributed across sellers, brands, categories, price points, and inventory. A change that improves buyer clicks may concentrate traffic on already-dominant sellers. A recommendation model may increase conversion while reducing exposure diversity. An ad treatment may increase monetization while cannibalizing organic discovery. A ranking change may shift demand rather than create it.
Standard buyer-level A/B testing can fail to capture these effects entirely. When treatment and control groups interact through shared inventory, shared attention, and shared competitive dynamics, the assumption that one user’s treatment does not affect another’s outcome can fail — and the experiment can return a biased result.
Marketplace experimentation research from Airbnb has shown this directly: standard randomized experiments can become biased when treatment and control groups interact through shared marketplace dynamics [6]. LinkedIn has discussed related challenges in networked and ads-marketplace experimentation, including cluster-based and budget-split approaches for settings where ordinary randomization may be biased or underpowered [7][8]. The implication for ecommerce is that buyer-level tests may systematically undercount the costs of changes that concentrate attention, reduce seller diversity, or shift demand from organic discovery toward paid placement — producing results that appear positive at the buyer level while obscuring real damage to the marketplace.
If a recommendation change increases purchases by moving attention from one set of sellers to another, the buyer-side metric may look positive while the marketplace effect is more ambiguous. If an ads change increases ad revenue but reduces trust in organic discovery, the short-term result may conceal a longer-term cost. If a ranking change improves head-query conversion but hurts long-tail discovery, the aggregate result may obscure strategically important damage.
This is why ecommerce experimentation needs marketplace-aware metrics: seller exposure, seller diversity, inventory coverage, long-tail performance, organic versus paid balance, repeat buyer behavior, and long-term marketplace health.
From experiment velocity to product learning
A mature experimentation platform can create a subtle organizational trap. Once it becomes easy to launch tests, experimentation velocity can become a proxy for innovation.
High experimentation velocity is a genuine organizational achievement, reflecting infrastructure maturity, analytical discipline, and cross-functional commitment. Running thousands of tests a year is a meaningful capability — but experimentation velocity is not equivalent to learning.
The conflation of the two tends to occur when organizations begin measuring the throughput of tests as a stand-in for the throughput of insight. Tests are visible, countable, and defensible — they produce dashboards, launch decisions, and clean narratives — whereas learning is considerably harder to measure. It may come from user testing, product discovery, qualitative feedback, failed experiments, surprising segment-level results, or slow changes in customer behavior.
Because experiments are easier to count than insights, organizations can start to track and reward the number of tests launched, the number of variants shipped, the number of wins, or the cumulative lift reported. These are useful operational measures, but they become risky when they function as proxies for innovation.
There is also a resource allocation problem. Learning from experiments requires scarce analytical bandwidth. A serious readout may require analysts and data scientists to examine segments, guardrails, instrumentation, novelty effects, and unexpected interactions. When high experimentation velocity ties up this bandwidth in routine test readouts, there may be less capacity for deeper analysis, metric development, or new hypothesis generation. The organization can then become throughput-heavy but insight-light: many tests are launched and read out, but too few are analyzed deeply enough to shape the next generation of ideas.
There is a genuine tradeoff here: should scarce analytical capacity be devoted to deeply understanding a completed experiment, or to supporting the next hypothesis — a new ranking feature, personalization strategy, or product experience? The answer is not always obvious, but the tradeoff needs to be managed deliberately.
When velocity becomes the dominant goal, it tends to compress everything else. Teams spend less time on discovery because the next test needs to launch. Design exploration narrows because smaller changes are easier to isolate. Development favors what can be built and measured quickly. Analysis attends to statistical significance rather than to the underlying causes of a result. Learning becomes a dashboard ritual rather than a deeper synthesis.
Neither failed tests nor successful ones should be treated as closed cases. Both should be mined for insight. A surprising result may reveal a hidden user need, a flawed assumption, a segment difference, a trust issue, a marketplace effect, or a larger product opportunity.
The purpose of experimentation is learning; throughput is a means to that end, not an end in itself.
When experiments become scorecards
A related but distinct challenge arises when A/B test outcomes are used as the primary mechanism for assigning credit to teams and measuring their performance against organizational goals. Used carefully, this approach has real advantages: experiment wins are legible, quantifiable, and directly connected to business outcomes, which makes it relatively straightforward to track progress, recognize team contributions, and communicate impact to leadership. In organizations where product value can otherwise be difficult to measure, the clarity that experiment-based performance measurement provides is genuinely useful.
The risk emerges when win rate becomes the dominant signal. Teams evaluated primarily on the accumulation of positive results will, over time, tend to run experiments designed to maximize the probability of a win rather than the value of what is learned. Rather than asking what is the most important thing the team could discover, the operative question shifts toward what can be tested that is most likely to produce a favorable result. The outcome is a portfolio tilted toward low-risk, incremental changes with a high prior probability of positive movement — work that is well-suited to generating wins but less suited to generating the deeper understanding the organization needs.
Bolder work tends to be crowded out by this dynamic. A new experience concept, a fundamental change to how the platform allocates attention, or a significant revision to the personalization strategy all carry a meaningful probability of a null or negative result. When the organizational incentive structure rewards wins and penalizes failures, the rational team-level response is to favor safer bets. Over time, this can produce a roadmap dominated by incremental changes while higher-variance, higher-value work is deferred.
There is also a subtler effect on how results are interpreted. When experiment outcomes carry organizational weight, there is natural pressure — typically implicit rather than deliberate — to find ways to declare success. A result that is marginally positive on the primary metric, or positive on a secondary metric while flat on the primary, may be reported as a win. Guardrail violations may receive less scrutiny than they warrant. These pressures do not require bad faith; they are a predictable response to a system in which experiment outcomes serve as performance measures.
The goal, then, is to preserve the accountability and legibility that experiment-based measurement provides while avoiding the incentive distortions that come from treating win rate as the primary signal. One approach is to complement win-based measures with explicit evaluation of hypothesis quality, experimental rigor, and the strategic value of what was learned — including from experiments that failed. A team that runs a smaller number of well-designed experiments, learns something consequential from several of them, and revises its product direction accordingly may be contributing more than a team that accumulates marginal wins with limited understanding of why they occurred, even if the latter looks more productive on a dashboard.
A better product-learning system
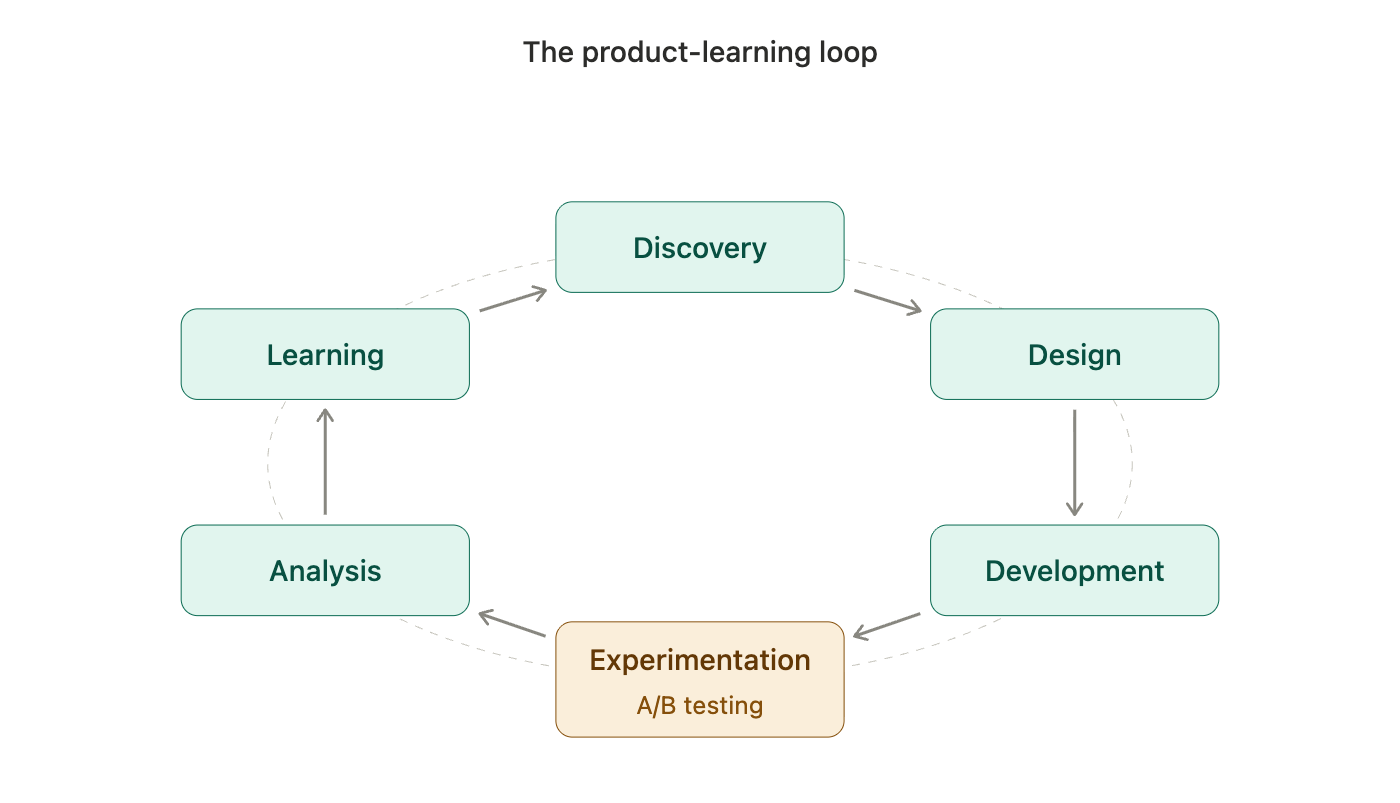
The answer is not to abandon A/B testing, but to restore it to its proper place — as one layer in a broader product-learning system, each layer answering a different question with the right method.
| Layer | Key question | Useful methods |
|---|---|---|
| Problem understanding | What are buyers trying to do? | User research, journey analysis, search logs, behavioral analysis, customer support themes |
| Solution development | What should we build? | UX exploration, prototyping, algorithmic development, catalog and intent modeling |
| Usability validation | Can users understand it? | User testing, heuristic review, comprehension testing |
| Causal validation | Does it work at scale? | A/B testing, interleaving, ramp tests, guardrail metrics |
| Experiment interpretation | What did we learn? | Post-test analysis, segmentation, diagnostics, hypothesis review |
| Long-term value | Does it improve the customer relationship? | Long-term holdouts, cohort analysis, repeat behavior, retention, satisfaction tracking |
| Marketplace health | Does it improve the system? | Seller metrics, exposure diversity, inventory coverage, marketplace-aware experiments |
This framing redefines what A/B testing is asked to accomplish. The experiment is no longer expected to discover the customer problem, invent the solution, diagnose the interface, measure long-term trust, and evaluate marketplace health all at once. Each layer does the work it is suited for, and each feeds the next.
Practical principles
For ecommerce discovery and personalization, the argument in this post can be distilled into six principles.
First, do not A/B test what users cannot understand. Use user testing to improve the quality of what reaches experimentation. If buyers cannot explain why they are seeing a recommendation, or if they confuse sponsored results for organic ones, the experiment will measure confusion as much as preference.
Second, take opportunity cost seriously. Time and resources devoted to optimizing a suboptimal experience are unavailable for the development of a superior one. A roadmap full of locally rational tests can still crowd out the deeper work needed for a step-change improvement. The relevant question is not only whether a given test produced a win, but whether the team is optimizing the right experience in the first place.
Third, do not let measurable metrics crowd out meaningful ones. Click-through rate, conversion, and similar short-window signals are useful, but they are not equivalent to trust, satisfaction, long-term customer value, or marketplace health. Prioritizing what can be measured in a two-week window carries real strategic risk when those metrics do not fully reflect the outcomes that actually matter.
Fourth, analyze heterogeneous effects. In personalized systems, averages can conceal important segment-level harm or opportunity. A treatment that improves average conversion may degrade the experience for niche buyers, cold-start sellers, or long-tail inventory — differences that deserve attention in their own right.
Fifth, measure marketplace impact, not just buyer behavior. Recommendations and ranking systems allocate attention across sellers and inventory. Buyer-level metrics alone will not reveal whether a change is improving the marketplace or slowly concentrating it.
Sixth, complement win-based performance measures with learning-based ones. Using experiment outcomes to track team progress and recognize contributions has real value — it connects effort to business impact and makes progress legible. The risk arises when win rate becomes the dominant signal, crowding out bolder work and creating pressure to declare marginal results as successes. Evaluating teams on hypothesis quality, analytical rigor, and the strategic value of what was learned — including from experiments that failed — helps preserve accountability without distorting the incentive to learn.
Putting A/B testing back in its proper place
A/B testing remains indispensable. It is one of the best tools available for measuring the causal impact of product changes. It has made digital product development more disciplined, more empirical, and less dependent on internal opinion.
A culture of experimentation is far better than a culture without it.
The next stage of maturity is not less experimentation. It is better-integrated experimentation: experiments connected to user insight, product judgment, technical depth, marketplace understanding, and long-term customer value.
In ecommerce discovery and personalization, the goal is not merely to accumulate statistically significant wins, even though many of those wins matter considerably. The goal is to help buyers find what they want, discover what they did not know to ask for, trust the platform, and return over time.
A/B testing can help us get there — but only when we treat it as one of the most powerful instruments within product learning, not as a substitute for it.
This is the first post in a short series on experimentation maturity. In the next post, I will discuss where AI can realistically help: not by automating product judgment, but by improving the learning loop around experiments. A third post will look at the relationship between AI evals and A/B testing.
References
[1] Ron Kohavi, Randal M. Henne, and Dan Sommerfield, “Practical Guide to Controlled Experiments on the Web: Listen to Your Customers, Not to the HiPPO.” KDD 2007. A foundational paper on online controlled experiments and the value of using experiments to move beyond opinion-driven product decisions.
[2] Alexander P. Miller and Kartik Hosanagar, “An Empirical Meta-analysis of E-commerce A/B Testing Strategies.” A large-scale analysis of 2,732 ecommerce A/B tests across 252 companies, showing that experiment outcomes vary substantially by intervention type and funnel location.
[3] Jakob Nielsen, “Why You Only Need to Test with 5 Users.” Nielsen Norman Group, 2000. A classic usability-testing article arguing for small, iterative user tests as a cost-effective way to uncover interface problems.
[4] Jakob Nielsen, “How Many Test Users in a Usability Study?” Nielsen Norman Group, 2012. A follow-up discussion of the “five users” heuristic, including caveats and practical guidance for qualitative usability testing.
[5] Carlos A. Gomez-Uribe and Neil Hunt, “The Netflix Recommender System: Algorithms, Business Value, and Innovation.” ACM Transactions on Management Information Systems, 2015. A useful reference on recommender-system evaluation, including the role of offline experimentation, A/B testing, retention, and medium-term engagement.
[6] David Holtz, Ruben Lobel, Inessa Liskovich, and Sinan Aral, “Reducing Interference Bias in Online Marketplace Experiments Using Cluster Randomization: Evidence from a Pricing Meta-experiment on Airbnb.” A marketplace experimentation paper showing how interference between treatment and control groups can bias ordinary randomized experiments.
[7] LinkedIn Engineering, “Introduction to the Technical Paper on LinkedIn’s A/B Testing Platform.” A practical industry reference on large-scale experimentation infrastructure, including network A/B testing, clustering, and experiment analysis.
[8] LinkedIn Engineering, “Budget-split testing: A trustworthy and powerful approach to marketplace experimentation.” A practical industry reference on marketplace experimentation for ads systems, where treatment and control groups may interact through shared budgets.

Leave a comment